





Doctor Droid is a YC backed company, building products for software developers that help them detect & diagnose their production incidents faster. They have recently built an alert enrichment & automation platform that enables service owners create investigation guides for on-call engineers with in-built support to query metric & log sources.
Context:
Back in summer of 2022, when we started out on the journey to help engineers do faster & more accurate detection of production incidents, we decided to build a hot storage for their events to support fast search on the events and create metrics through aggregations which can then be tracked via simple alerts.
For instance, an user should be able to create this flowchart by aggregating and joining events:

Apart from capability of joining and aggregating events, following are the features that we promised our customers when we launched:
| Source Integrations | Events Ingestion | Events Storage | User Features |
| Segment | Event drop guarantees | Source of Truth | Search |
| AWS Kinesis Firehose | Real-time processing | Fast-analytics | Metrics |
| SDK / API | Asynchronous processing | High performance on aggregation & search | Condition based alerts |
Early Start with v0
Since we were trying to get our first customer, as a prototype, we started out as a simple Django + PostgresDB setup. Since our customer events were unstructured, we had leveraged the json features of Postgres to store them. Below is how our v0 architecture looked like:
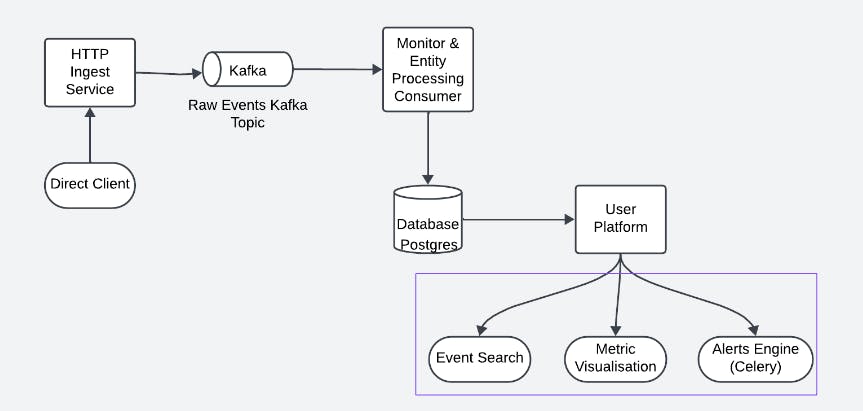
But, as soon as we scaled a bit, we realised that PostgresDB has no legs to scale and we were becoming a sluggish interface for our customers. We decided to move to an OLAP database which will allow us to achieve our search & aggregation goals. However, when we researched for popular analytics databases, we realised that hardly any of them supported the json equivalent features. With mandates of upto 150M+ daily events from our customers, we were running out of time. This is what we could achieve with Postgres:
Performance on PostgreSQL (v0)
| Events Volume | 25-50k events/day |
| Aggregation API | <insert the api benchmark image> |
| Search API | Asynchronous |
We evaluated some storage solutions that would work for our needs
| ClickHouse | Pinot | ElasticSearch | |
| Storage | Columnar with parts optimised for querying across the dataset | Columnar with chunks with custom index, optimised for max data freshness | Inverted index storage, optimizing for quick full-text search and aggregations. |
| Maintenance | Single component deployment | Extensive fine-tuning & manual configuration, multiple components (Controller, Zookeeper, Broker, Server) | Difficult with non-strict schema – due to mapping explosion / multi-tenancy issues |
| Schema Flexibility | High | Low – with manual definition and updation |
Clickhouse had recently added an experimental feature to allow json columns which can be enabled using a simple command. This allows a PostgreSQL type capabilities to add unstructured json objects in a column. Clickhouse internally manages the global set of keys in the json objects across all rows as hidden columns which are as fast to query against as any other column. However, there is an upper limit of 10K unique keys that are allowed in in a table. We signed up for an account on Clickhouse cloud and our migration was underway.
Introducing v1
Here is the modified architecture after we included Clickhouse:

With this migration, our search and aggregations become within the benchmarks we wanted to setup for our customer experience.
Following are the specs we work with today:
Databases:
Postgres DB (Main + Replica) : db.m6i.large (2 vCPUs, 8GB Memory)
Clickhouse Cloud DB : (4 vCPUs, 16GB Memory) X 3 Replicas
Kafka:
3 Broker Cluster (Each having 2 vCPUs, 8GB Memory, 200GB Disk)
Same cluster manages all topics
Platform:
Python, ReactJs
Deployed on AWS Kubernetes Engine
Scales we have tested:
- 150M+ logs/day with this config with a TTL of 15 days
While our unstructured schema handling is highly dependent on json support from Clickhouse, there has been discussions lately from the Clickhouse authors that this particular way to support json isn’t working out great and they would probably sunset this experimental feature soon. Check out the video to learn about one of the issues we faced while using the experimental JSON feature and it’s impact.
There are some other ways to manage unstructured data storage with ClickHouse which we will explore in the near future to make sure our products stay on track to fulfil what our customers are looking for. You can read more about them here.