

Spend 10x less time debugging with PlayBooks
An approach that will help reduce your debugging time significantly.

Debugging is a core part of any engineering job. While developers often aspire to build products and platforms, they often end up spending significant amount of time in running manual operations.
In this blog, I'll walk you through how you can use PlayBooks to reduce the time you spend debugging.
What are PlayBooks?
PlayBooks is an open source tool to write executable notebooks for on-call investigations / remediations instead of Google Docs or Wikis.
How do PlayBooks help accelerate debugging?
PlayBooks will help you in three scenarios:
Scenario 1: A common issue with multiple possible reasons for failure
Imagine a failure alert for one of your daily cron jobs. That failure needs to be investigated before you rerun the cron job to avoid the same issue again. So you'd ideally go and check the reason for the issue and validate it.
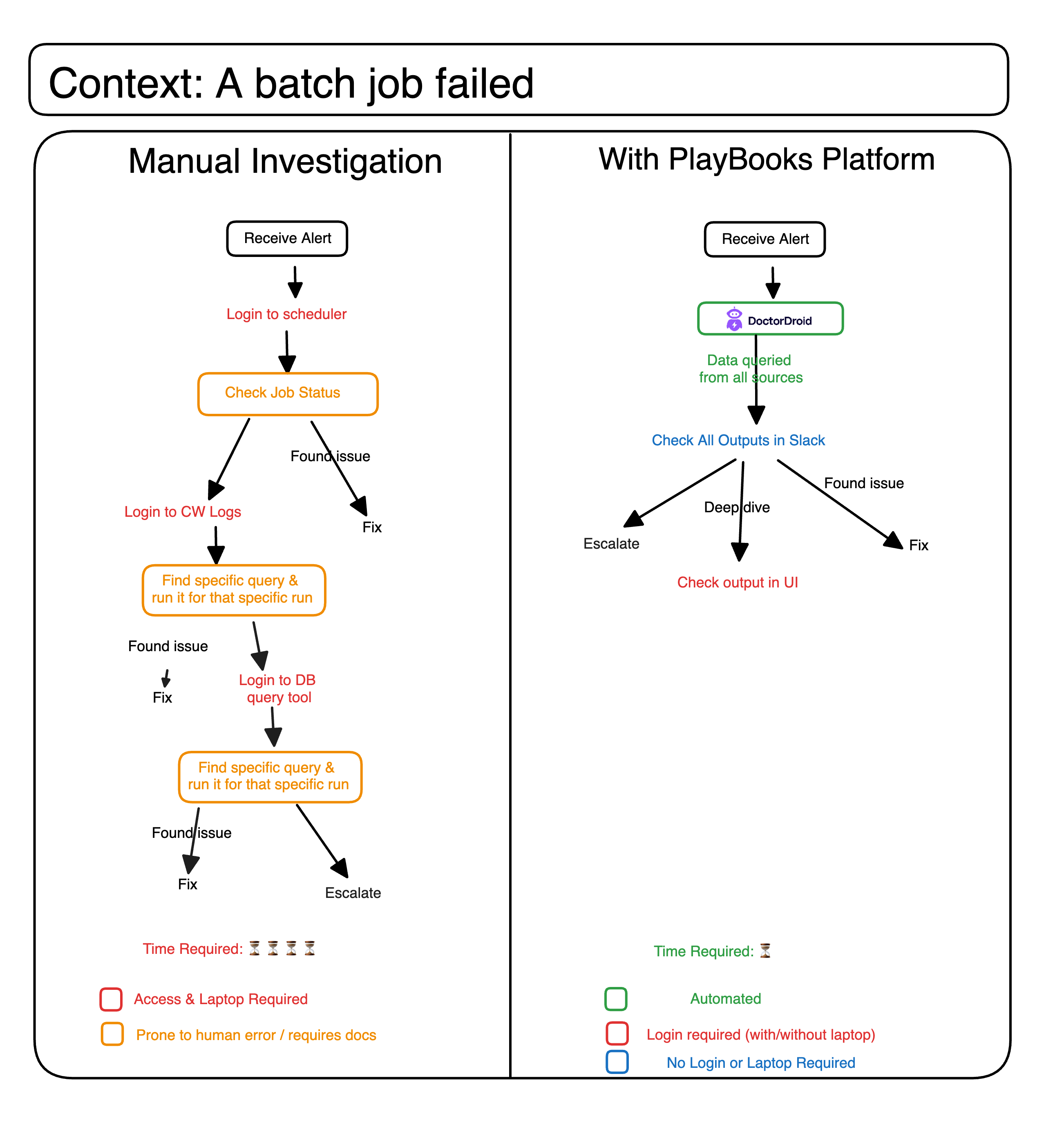
Before PlayBooks:
You might need to first check the status of your cronjob in your scheduler, then go to logs to see the respective error message and also check the related data (that's being used in the job) in DB to validate for "correctness" of the data.
Steps to follow manually:
Login to your scheduler
Search for the failed job and it's status
Login to Cloudwatch or your logging tool (assuming you have access to it)
You'll login to Cloudwatch Logs, copy paste a query you might have stored in your notepad or google doc. Then edit the job id and search for logs.
Once you get a cue on the failure reason, you decide to go to Database and then check relevant files using another query pinned in Slack channel.
After PlayBooks:
With PlayBooks here's how it would have happened:
PlayBooks would automatically read job_id from your alert message.
Auto-run the fetching steps from your logs, scheduler and database.
Output from different sources automatically sent as response to alert in Slack.
Before the developer even had to login, they were able to see the relevant data points to decide what action needs to be taken and where.
(Even the action can be automated, but we will discuss that later)
Scenario 2: Late night on-call issue
You are a senior developer and lead for a service. This service is business critical and one of the engineers from the team is on-call.
An escalation from business comes up in the Slack that your service is not behaving as expected (user unable to login) and customers are impacted.
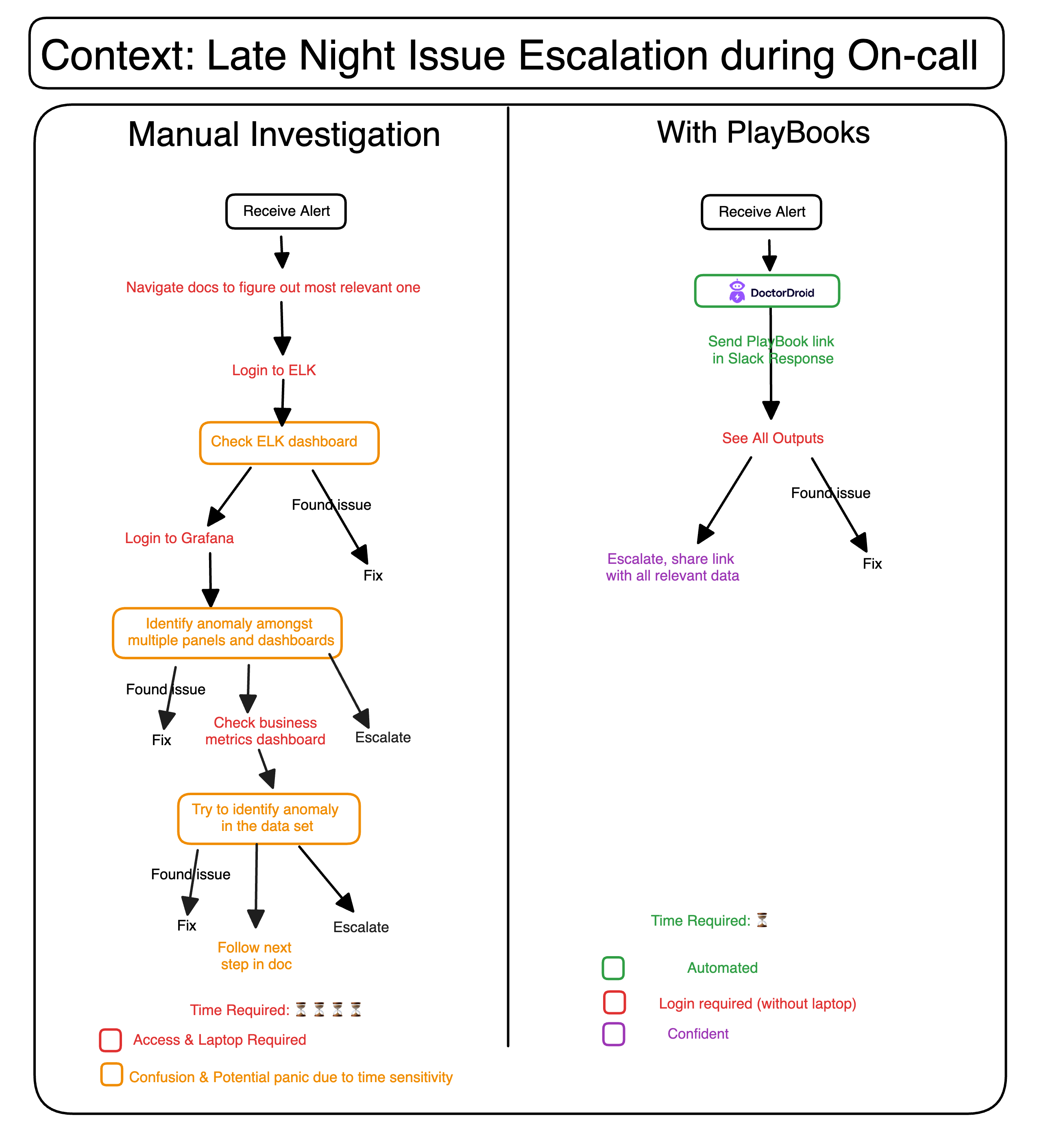
Before PlayBooks:
Your on-call developer logged in to the laptop, tried to understand the issue from alert and figure out which document to follow (there were 5 of them). Once identified, he decided to do the first step that said, check this ELK dashboard -- oops he hadn't logged in into ELK in a while and switched laptop. He figures out the login (somehow. read: asking another oncall) and logs in. Tries to analyse the dashboard, everything looks alright.
Next step says he needs to check the Grafana dashboard. He's trying to navigate -- the dashboard has too many graphs and 5 minutes later, he couldn't find an issue as the spikes were all normal.
As a last resort, he also checks the product wide dashboard which has more data. Couldn't find anything, and he reaches out to you.
You know all the weakpoints of your service, quickly diagnose and identify that a downstream service was throwing an unexpected error due to a database cpu-limit-breach. You share screenshots of the issue and escalate the issue.
You know that the service dependencies were mentioned in the service document but on-call dev ended up escalating before reaching there due to time sensitivity.
Everyone thanks you, on-call engineer feels a little bad but goes on to create the postmortem and moves on. Your family is a bit annoyed but can't complain, it's a part of the job, ain't it?
With PlayBooks:
Using PlayBooks, all of these steps (ELK, Grafana, upstream/downstream service checks) could have been automated and your on-call would have received the link to the PlayBook in the alert response.
They would have gone in the PlayBooks, run it step by step within 10 seconds and seen the output.
The fifth step (that he didn't reach upto previously) showed the anomaly and he instantly shared the PlayBook link in the channel with multiple teams. Everyone saw the data from the on-call's run and was able to quickly validate the issue.
The team now takes handover, quickly fixes the issue and system is back to normal. You didn't need to get involved although the PlayBooks link was helpful for you to check in (from the phone).
What if it was a new issue and nobody knew about it?
Of course, that happens often but even in that situation, the context transfer and the time to get up to speed would have been much faster with PlayBooks that without.
Scenario 3: Continuous monitoring
You are a lead for a new feature development. You just did a critical deployment with some breaking changes for a couple of services. Post deployment, you had to make a hotfix. Post the hotfix, you want to ensure that your team is on top of all data and knows instantly if stability is not reached.
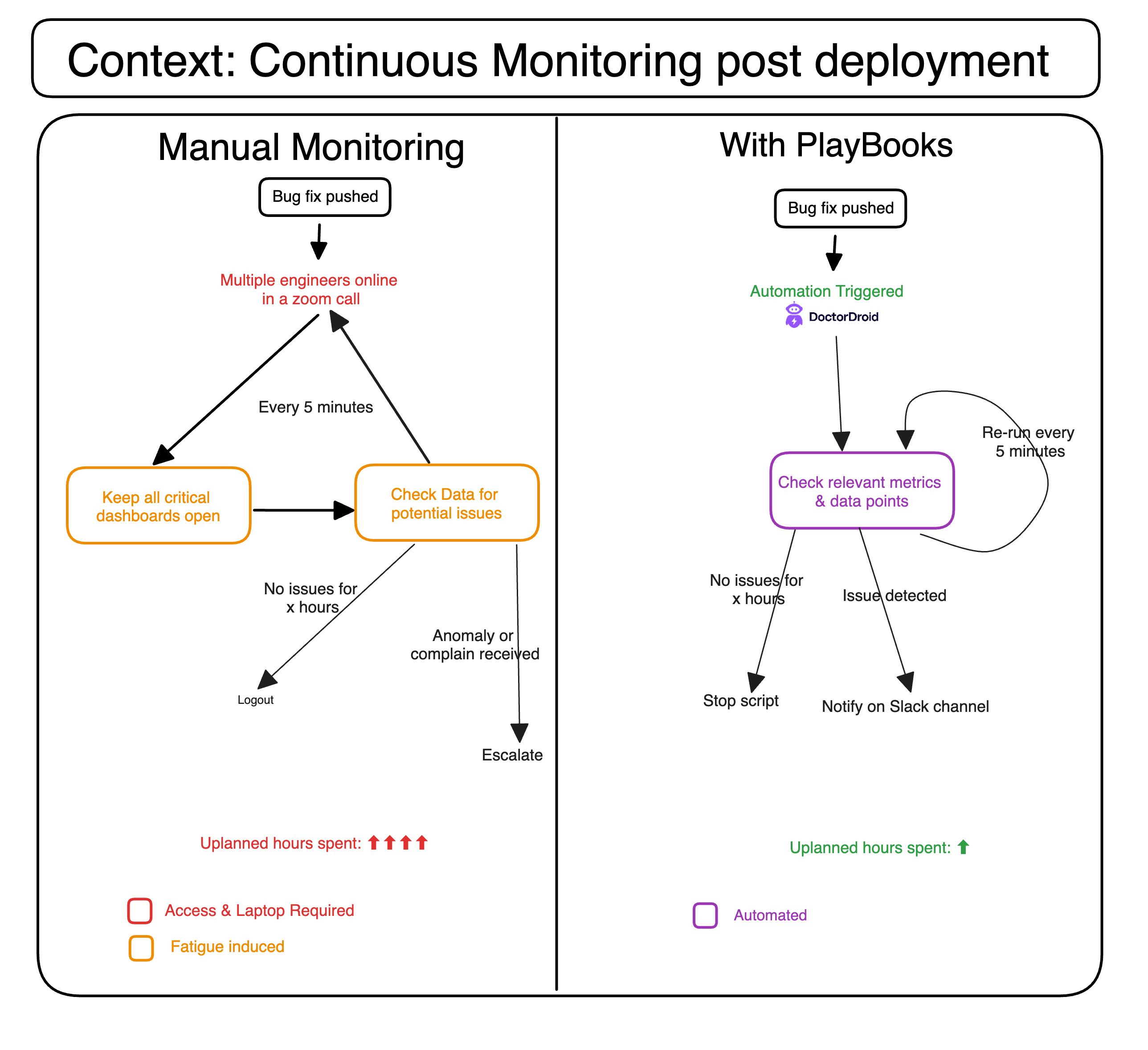
Before PlayBooks:
You along with a set of engineers are together on a zoom call and are continuously refreshing dashboards every few minutes to check improvement of metrics. After an hour, your team decides to cool off. The next working day, half of them logged in late and felt a fatigue so it caused a delay in your sprint plan.
After PlayBooks:
Your team has configured a checklist for service health tracking with all the custom data points that you want to track. You've scheduled a workflow that runs every 5 minutes for 4 hours and updates you if it doesn't find the data moving towards stability.
You check data once-in-a-while but your team knows that anomalies will be highlighted instantly by PlayBooks.
If you and your team are feeling you spend too many unplanned hours on issues that are non-critical, here's your time to try out Doctor Droid's PlayBooks.




